2024-02-23
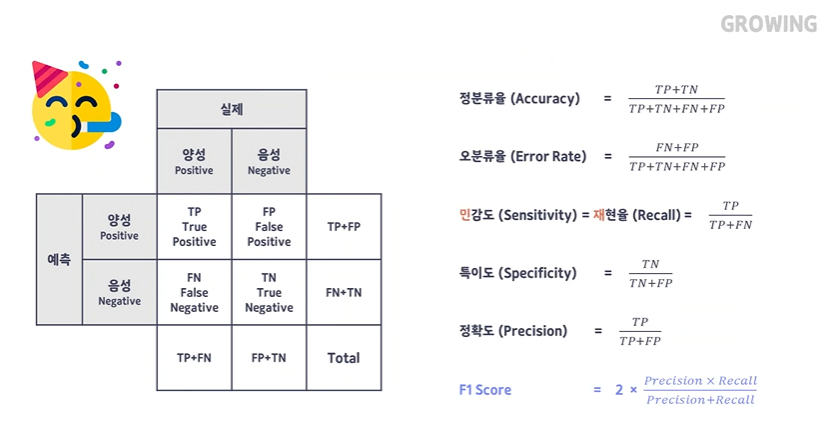
오차행렬 (Confusion Matrix)

※ comment
표 밖의 지표, 예측과 실제가 어디에 있는지,Positive 와 Negative 자리부터 잘 확인해야한다.
자격증별로, 사람마다 잘 쓰는 순서가 달라서 위치로 외워 버리면 헷갈리기 때문에 유의한다.
지표 읽는 방법 뒷자리 -> 앞자리 로 보는 것이 편하다.
내가 만든 모델이 P(긍정)으로/ N(부정)으로 예측했는데 ->그 값이 실제로 T(참, 맞았다.) / F(거짓, 틀렸다.)
| 앞자리 | 뒷자리 | ||
| 실제값 | 내가 만든 모델이 예측한 것 | ||
| P(긍정) 1 |
N(부정) 0 |
T(참, 맞았다.) 1 |
F(거짓, 틀렸다.) 0 |
정분류율 Accuracy : 전체 경우에서 모델이 정답을 맞춘 경우 => True 들만 분자로
정확도 Precision : 모델이 True라고 예측한 것 중에서 진짜 True 의 개수 = 모델이 고른 모든 Positive(TP+FP) 중 TP
재현율 Recall : 원래 데이터가 True 인 것 중에서 모델이 True 라고 맞춘 개수 = TP + FN 중 TP
(※ 정확도와 재현율 헷갈릴 수 있으니 유의)
F1 Score : Precision 과 Recall 의 중간값을 확인하기 위해 새롭게 만들어진 지표.
ㄴ 정확도와 재현율이 모두 높을 수록 1에 가까운 값을 가진다. (최대 1의 값을 가질 수 있다.)
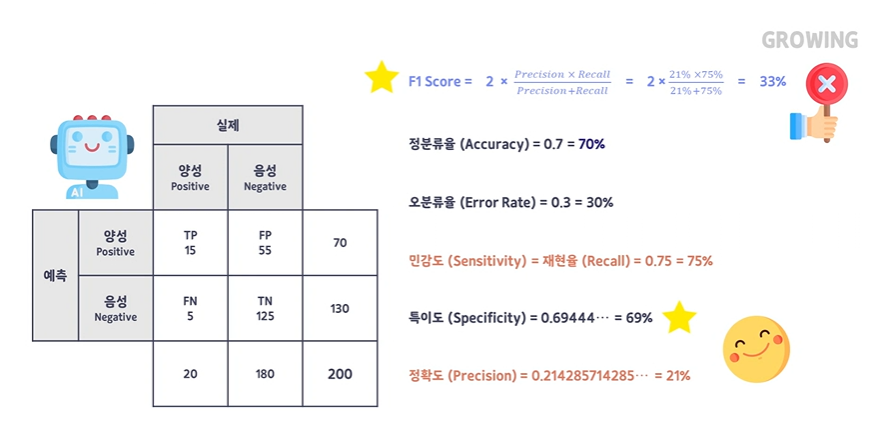
스코어 작업 : 평가데이터와 - 모델 예측값을 하나하나 매칭하는 것
문제풀이

관심있고 찾아내고 싶은 것을 = True 라고 지정해 놓는다.
(정상인 게 아니라!)
따라서 스팸메일과 비정상 세포를 True 라고 설정해 놓는다.
복습 2024-02-25
https://www.youtube.com/watch?v=VbJHlCDOteU
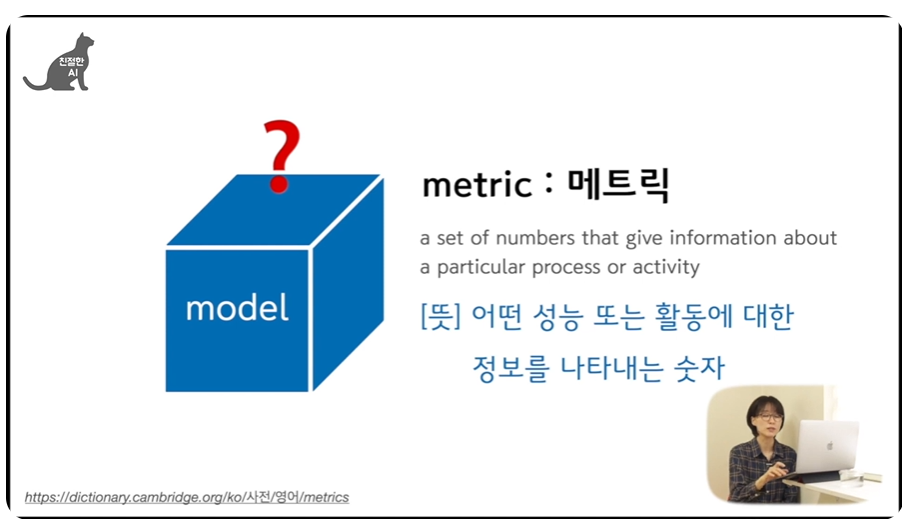
원래의 metric : 메트릭 의미
[의미] a set of numbers that give information about a particular process or activity
[해석] 어떤 성능 또는 활동에 대한 정보를 나타내는 숫자
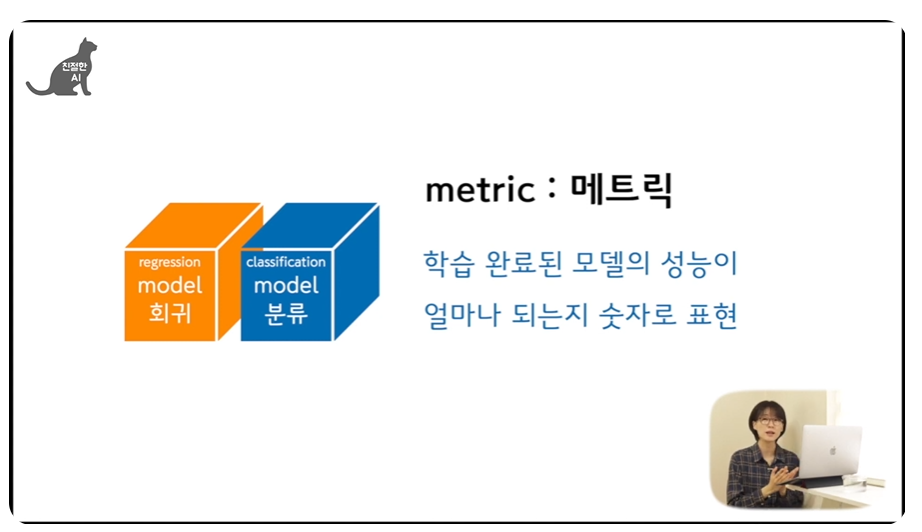
in 머신러닝
metric : 학습 완려된 모델의 성능이 얼마나 되는지 숫자로 표현
☞ 내가 학습 시킨 모델의 종류에 따라 ☞ 살펴봐야 하는 지표의 종류도 분화, 다양하다.
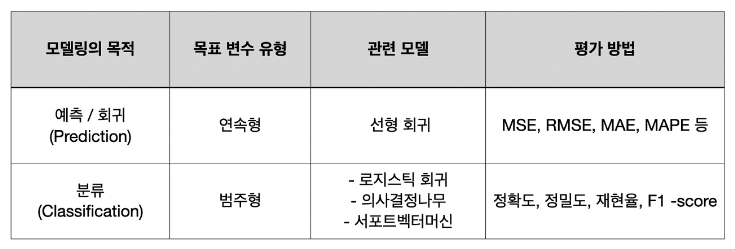
지도학습의 양대 산맥 : ①회귀와 ②분류 모델
| 지도학습 | 모델의 종류 (분류 기준) 지도학습의 경우 머신러닝을 통해 예측하고자 하는 값이 실수(숫자) | 범주형 변수에 따라 회귀 모델과 분류 모델로 나뉜다. |
|
| Regression Model 회귀 모델 |
회귀(regression) 는 예측하고자 하는 타겟값이 실수, 즉 숫자인 경우 이다. 그리고 회귀는 예측 결과가 연속성을 지닌다. 여기서 연속성이란, 말그대로 연속하는 값을 말한다. 예를 들면, 1.2, 1.201, 1.2001 처럼 연속성을 지닌는 것을 뜻한다. 회귀를 통해 손해액, 매출량,거래량, 파산할 확률 등을 예측할 수 있다. 즉, 회귀문제란 실수형 변수를 통해 예측하여 예측 결과값이 연속성을 지니고 있는 경우 회귀문제라고 할 수 있다. | |
| Classification Model 분류 모델 |
분류(classification) 는 예측하고자 하는 타겟값이 범주형 변수인 경우 이다. 회귀와는 다르게 분류는 예측 결과가 연속성을 지니지 않는다. 연속성을 지니는 연속값이 아닌 이산값을 가지고 있다. 여기서 이산값이란, 0과1로 처리할 수 있는 값으로써 연속적이 아닌 단속적인 값을 뜻한다. 분류를 통해 부도 여부(yes/no), 여신 승인 여부, 동물 분류(dog/cat) 등을 예측할 수 있다. 분류의 종류에는 이진분류와 다중분류가 있다. 이진분류(binary Classification)는 Yes/ No처럼 두가지의 답으로 분류하는 것을 뜻한다. 다중분류(multiclass Classification)는 이진분류에서 답의 갯수만 증가한 분류의 형태이다. 즉, 분류문제란 범주형 변수를 통해 예측하여 예측 결과값이 이산값을 지니고 있는 경우 분류문제라고 할 수 있다. |
|
| 회귀 vs 분류 - 개념 (영상학습) https://opentutorials.org/module/4916/28942 |
||
https://www.youtube.com/watch?v=Eyxynd-vDsQ
'#단편모음 > 개념 ( 이해와 정리 )' 카테고리의 다른 글
| [결측 데이터의 종류] MCAR, MAR, NMAR (1) | 2024.03.17 |
|---|---|
| [프라이버시 모델] k-익명성 → l-다양성 → t-근접성 (개인정보 비식별 조치) (1) | 2024.03.17 |
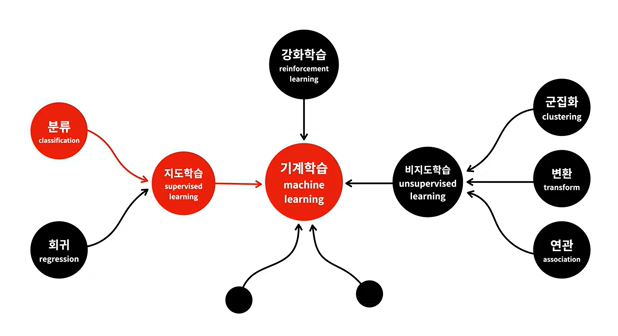
| [기계학습과 종류] 지도학습, 비지도학습, 기계학습 (0) | 2024.02.23 |
| [척도] 명목척도 서열척도 등간척도 비율척도 (0) | 2024.02.22 |



